HTR voor Archieven en Historische Documenten
Handwritten Text Recognition met AI: van onleesbare 17e-eeuwse akten tot doorzoekbare digitale collecties
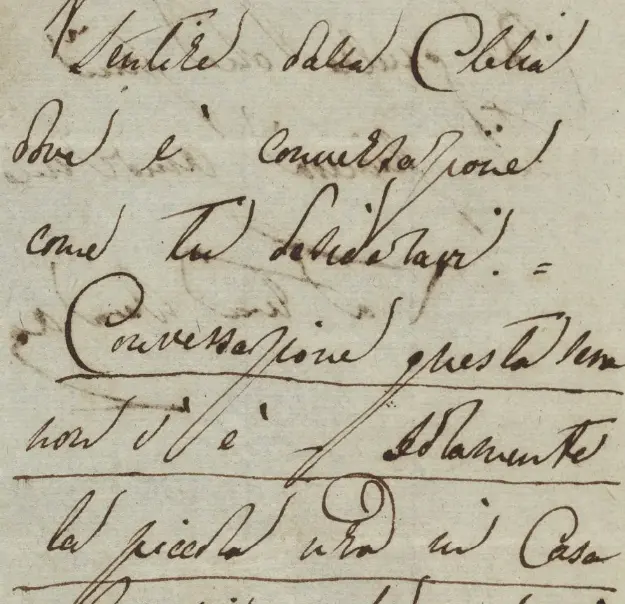
Wat is HTR (Handwritten Text Recognition)?
HTR staat voor Handwritten Text Recognition, de technologie die handgeschreven tekst automatisch omzet naar digitale, doorzoekbare tekst. Anders dan traditionele OCR, die alleen gedrukte tekst herkent, is HTR specifiek ontwikkeld voor de uitdagingen van handschriften.
Moderne HTR gebruikt deep learning en neurale netwerken om patronen in handschriften te herkennen. Het systeem leert van voorbeelden en wordt nauwkeuriger naarmate het meer materiaal verwerkt. Dit maakt het mogelijk om zelfs lastige historische handschriften te ontcijferen.
Voor archieven en erfgoedinstellingen opent HTR nieuwe mogelijkheden: collecties die voorheen alleen toegankelijk waren voor paleografen worden nu doorzoekbaar voor iedereen. Lees meer over het verschil met ICR voor zakelijke documenten.

Waarom EasyData voor HTR?
We combineren 25+ jaar documentverwerking-expertise met de nieuwste AI-technologie
Custom AI-modellen
We trainen specifieke modellen op jouw collectie voor maximale nauwkeurigheid.
Nederlandse partner
Direct contact, geen taalbarriere. Je data blijft in Nederland.
ALTO XML & TEI output
Standaard archiefformaten voor naadloze integratie.
Human-in-the-loop
Menselijke verificatie bij twijfelgevallen voor 100% zekerheid.
Systeemintegratie
Koppeling met bestaande archiefsoftware en DAM-systemen.
Schaalbaar
Van 100 pagina’s pilot tot honderdduizenden scans bulk.
ABBYY partnership
Toegang tot ‘s werelds beste OCR-technologie als basis.
Expertise delen
We trainen je team in het werken met HTR-resultaten.
EasyData HTR vs. Self-service platforms
Kies voor begeleiding of doe het zelf
🌐 Self-service HTR (zoals Transkribus)
- Zelf aan de slag met tutorials
- Community-modellen beschikbaar
- Gratis credits voor starters
- Grote internationale community
- Geschikt voor individuele onderzoekers
- Zelf modellen trainen (learning curve)
🏢 EasyData HTR (managed service)
- Persoonlijke begeleiding door experts
- Wij trainen de AI-modellen voor je
- Nederlandse AVG-compliant verwerking
- Integratie met archiefsystemen
- Bulk-verwerking mogelijk
- 25+ jaar documentverwerking expertise
HTR voor historische documenten
Van middeleeuwse manuscripten tot 20e-eeuwse archieven
Notariele akten
17e en 18e-eeuwse akten met varierende handschriften.
Kerkelijke registers
Doop-, trouw- en begraafregisters doorzoekbaar maken.
Manuscripten
Literaire manuscripten en dagboeken digitaliseren.
Overheidsarchieven
Raadsnotulen en bestuurlijke correspondentie.
Briefcollecties
Persoonlijke correspondentie omzetten naar tekst.
Tabellen en lijsten
Registers en inventarissen met complexe lay-outs.
Kadastrale stukken
Historische kadasterakten en meetbrieven.
Scheepvaartarchieven
Scheepsjournalen en VOC-documenten.
Hoe werkt een HTR-project?
Van eerste gesprek tot doorzoekbare collectie
Intake & analyse
We bekijken je materiaal: periode, taal, handschriftvariatie en documentconditie. Gratis haalbaarheidsadvies.
Pilot
Test met 100-500 pagina’s om nauwkeurigheid te meten. We trainen een eerste AI-model op jouw collectie.
Modeloptimalisatie
Op basis van de pilotresultaten verfijnen we het model. Ground truth correcties verhogen de nauwkeurigheid.
Bulk-verwerking
De volledige collectie wordt verwerkt. Doorlooptijd afhankelijk van omvang, doorgaans weken tot maanden.
Levering & integratie
Je ontvangt ALTO XML, TEI of ander gewenst formaat. Optioneel: integratie met je archiefsysteem.
De techniek achter HTR
Neural networks: Moderne HTR gebruikt Convolutional en Recurrent Neural Networks (CNN/RNN) om visuele patronen in handschrift te herkennen. Het systeem leert niet alleen individuele letters, maar ook woordcontexten.
Character Error Rate (CER): Dit is de standaard metric voor HTR-kwaliteit. Een CER van 5% betekent dat gemiddeld 1 op de 20 karakters fout is. Voor goed leesbare documenten halen we doorgaans 3-5% CER.
Ground truth: Om een model te trainen heb je correct getranscribeerde voorbeelden nodig. Hoe meer en beter je ground truth, hoe nauwkeuriger het model wordt.
Transfer learning: We starten vaak met een basis-model dat al getraind is op miljoenen pagina’s, en fine-tunen dit op jouw specifieke collectie. Dit verkort de trainingstijd aanzienlijk. Lees meer over onze machine learning aanpak.
Veelgestelde vragen over HTR
HTR staat voor Handwritten Text Recognition, oftewel handgeschreven tekstherkenning. Het is een AI-technologie die historische en moderne handschriften automatisch kan lezen en omzetten naar doorzoekbare digitale tekst. Anders dan OCR, dat alleen gedrukte tekst herkent, is HTR specifiek ontwikkeld voor de complexiteit van handgeschreven documenten.
De Character Error Rate (CER) geeft aan welk percentage karakters fout wordt herkend. Bij goed leesbare historische documenten halen we doorgaans een CER van 3-5%, wat betekent dat 95-97% van de karakters correct wordt herkend. Bij lastige handschriften of beschadigde documenten kan dit hoger liggen. We geven altijd transparant aan wat je kunt verwachten.
Ja, we hebben ervaring met historische handschriften uit verschillende periodes, van middeleeuwse manuscripten tot 20e-eeuwse documenten. Voor oudere teksten met paleografische uitdagingen trainen we specifieke AI-modellen op jouw collectie. Dit verhoogt de herkenningsnauwkeurigheid aanzienlijk. We werken graag samen met je eigen paleografen of historici voor de ground truth.
Transkribus is een uitstekend self-service platform met een grote community. EasyData biedt HTR als managed service met persoonlijke begeleiding. Onze voordelen: Nederlandse partner met 25+ jaar ervaring, AVG-compliant verwerking in Nederland, integratie met bestaande archiefsystemen, en flexibele output naar ALTO XML, TEI of andere formaten. Ideaal voor instellingen die niet zelf willen trainen of integratie nodig hebben.
We leveren HTR-resultaten in diverse formaten: ALTO XML (voor integratie met archiefsystemen), TEI XML (voor academisch onderzoek), PAGE XML, plain text, doorzoekbare PDF, JSON, en CSV. Ook custom formaten voor specifieke archiefsoftware zoals Memorix of Atlantis zijn mogelijk. Coordinaten per woord of regel kunnen worden meegeleverd voor highlighting.
Dit hangt af van de omvang en complexiteit. Een pilotproject met 100-500 pagina’s duurt meestal 2-4 weken inclusief modeltraining. Grotere collecties van duizenden pagina’s verwerken we in fasen, vaak enkele maanden. Bulk-verwerking van honderdduizenden pagina’s is mogelijk met voldoende doorlooptijd. We geven altijd vooraf een realistische planning.
De kosten zijn afhankelijk van volume, complexiteit en of modeltraining nodig is. Een pilotproject start vanaf circa 1.500 euro. Bulk-verwerking wordt geprijsd per pagina, met staffelkortingen bij grote volumes. Neem contact op voor een vrijblijvende offerte gebaseerd op jouw specifieke collectie en wensen.
Klaar om je collectie te ontsluiten?
Start met een vrijblijvend gesprek. We bekijken je materiaal en geven eerlijk advies over haalbaarheid en verwachte resultaten.
🎯 Wat je van ons mag verwachten
Gratis haalbaarheidsadvies – We beoordelen je materiaal en geven eerlijk advies over verwachte resultaten.
Pilot vanaf 100 pagina’s – Test met je eigen documenten voordat je besluit. CER-rapport inbegrepen.
Nederlandse AVG-compliance – Alle verwerking op servers in Nederland. Verwerkersovereenkomst standaard.
25+ jaar expertise – Van OCR-pionier tot HTR-specialist. Persoonlijke begeleiding door ervaren team.
